Agentic Documentation Pipeline Series – Creating an Ontology

In a previous post, I argued that the technical writer’s role is shifting from content creator to systems architect. I have decided to write a series that walks through what an agentic documentation pipeline actually looks like in a production environment, with the tools, schemas, and decisions that make it work.
This post focuses on the first step in building the agentic documentation pipeline, which is creating an ontology.
What is an ontology?
An ontology is a formal, machine-readable model of the entities in a domain and how they relate. It is not a glossary, which only defines terms. It is not a content inventory, which only lists pages. It is a structured description of what the things in your product are, how they connect, and what facts about each one an automated system needs to know. In an agentic documentation pipeline, the ontology is the substrate the agent reads from before it writes anything. Without it, the agent sees a stream of unstructured text. With it, the agent sees a connected model of the product, which is exactly what it needs to produce documentation that holds together across thousands of pages.
The scenario
To ground the theory using a real life practical examples I am going to work with the following scenario:
- A mid‑stage Fintech company ships a payments API, a Node SDK, and a Python SDK to several thousand developers. In this company, engineers merge between three and ten pull requests per day.
- The company has the following:
- A monorepo on GitHub
- An OpenAPI 3.1specification as its API contract
- PRDs and design specs in Notion
- An existing Mintlify‑hosted documentation portal
Creating the Ontology
Before any AI writes a word, you need a machine‑readable description of the product. For an API‑led company, the natural place to start is the OpenAPI specification.
However, OpenAPI describes each endpoint in isolation. It tells you the URL, the parameters, the response shape. What it cannot tell you is how endpoints relate to each other, what happens after a request succeeds, or which guide a developer should be reading when they call this thing. Those relationships are exactly what good documentation has to express, and they live outside the spec.
The ontology has two layers:
- Per-endpoint metadata- you can attach it inside the OpenAPI spec using x- extensions.
- Cross-cutting relationships between concepts, flows, and pages - those need their own file because OpenAPI has no place to put them.
Layer 1 - Adding per-endpoint metadata
We can add that context with custom extensions. OpenAPI permits any field prefixed with “x-“. We will use the this prefix in the following manner:
- x-audience(developer, platform admin, finance ops) and x-personas (merchant, marketplace, issuer) – this let the agent pick the right register: a merchant integration page reads differently from a platform-admin one, and the same endpoint can appear in both with different framing.
- x-stability (stable, beta, deprecated) – this drives the visual treatment, the inclusion of a “beta” callout, and the change-log entry.
- x-flow (checkout, refund, payout, dispute) – this is what the orchestrator uses to assemble higher-level guides; every endpoint tagged checkout becomes a candidate section in the checkout integration guide, in the order the flow defines.
- x-example-realistic(used in parameters) - a sample value drawn from the test environment rather than the placeholder values authors tend to default to. This eliminates the most common defect in generated reference content, which is parameter examples like "string" or "abc123". By drawing from real test-environment IDs, the generated samples are copy-pasteable into a sandbox call.
- x-troubleshooting-anchor (used in error responses) – a link target that the troubleshooting agent can resolve. This lets the agent insert a working link next to every documented error code without having to invent the URL or guess the slug.
Here is a single, realistic OpenAPI fragment that exercises all four endpoint-level fields, plus x-example-realistic at the parameter and schema levels and x-troubleshooting-anchor on the error responses.
paths:
/payment_intents/{id}/confirm:
post:
summary: Confirm a payment intent
x-audience: developer
x-stability: stable
x-personas: [merchant, marketplace]
x-flow: checkout
parameters:
- name: id
in: path
required: true
schema:
type: string
x-example-realistic: pi_3OqK2pLkdIwHu7ix1PqRfTwz
requestBody:
content:
application/json:
schema:
type: object
properties:
payment_method:
type: string
description: Payment method to attach before confirming.
x-example-realistic: pm_1OqK2pLkdIwHu7ixYBN8aQjT
return_url:
type: string
description: URL to redirect to after off-session authentication.
x-example-realistic: https://merchant.example.com/checkout/return
responses:
'200':
description: Payment intent confirmed.
'402':
description: The payment was declined by the issuer.
x-troubleshooting-anchor: /troubleshooting/declines#card-declined
'409':
description: The intent is in a state that does not permit confirmation.
x-troubleshooting-anchor: /troubleshooting/state-conflicts#confirm-after-cancel
Layer 2 - Adding cross-cutting relationships between concepts, flows, and pages
The second layer captures everything that connects endpoints to each other and to the world outside the spec. We keep it in a set of catalog-info.yaml files in the repository, one per concept, flow, or webhook. Each file declares a single entity and the relationships it participates in. The files are validated against a schema on every PR, the same way OpenAPI is validated.
Three kinds of entries cover almost everything we need:
- Concept – a stateful resource such as a payment intent, with its states, transitions, and the endpoints that drive each transition. Once the agent knows that
POST /payment_intents/{id}/confirmmoves the resource from requires_actionto processing, every reference page for that endpoint can describe the state change without the writer having to add the sentence by hand. The same metadata feeds an auto-generated state diagram into the integration guide. - Flow – the canonical happy path through a sequence of endpoints, such as a checkout. The flow lists the steps in order, and the orchestrator uses it to assemble or refresh the tutorial that walks a developer through them. When an engineer inserts a new step, the tutorial regenerates with the step in the right place.
- Webhook – a first-class entity that OpenAPI does not describe well. The catalog captures which concept emits the webhook, which schema it carries, and where it is documented. The agent uses these links to cross-reference webhook payloads from the endpoint reference page that triggers them.
Two relationship fields appear on most entries:
- relatedConcepts drives the "See also" sections on every generated page without anyone having to maintain them by hand.
- documentedIn tells the orchestrator which pages depend on this entity, so that when an entry changes the right pages are queued for regeneration.
A condensed catalog excerpt for the running scenario looks like this:
apiVersion: docs.example.com/v1
kind: Concept
metadata:
name: payment-intent
spec:
type: stateful-resource
states: [requires_action, processing, succeeded, canceled]
transitions:
- from: requires_action
to: processing
triggeredBy: POST /payment_intents/{id}/confirm
emits: payment_intent.processing
- from: processing
to: succeeded
emits: payment_intent.succeeded
- from: any
to: canceled
triggeredBy: POST /payment_intents/{id}/cancel
relatedConcepts: [refund, payment-method]
documentedIn:
reference: /api/payment-intents
guides:
- /integrations/marketplaces/accepting-payments
---
apiVersion: docs.example.com/v1
kind: Flow
metadata:
name: checkout
spec:
personas: [merchant, marketplace]
steps:
- POST /payment_intents
- POST /payment_intents/{id}/confirm
- WEBHOOK payment_intent.succeeded
documentedIn:
guide: /integrations/marketplaces/accepting-payments
---
apiVersion: docs.example.com/v1
kind: Webhook
metadata:
name: payment_intent.succeeded
spec:
emittedBy: payment-intent
schema: components/schemas/PaymentIntent
documentedIn:
reference: /api/webhooks/payment-intent-succeeded
The documentation team owns the catalog schema and is responsible for keeping it useful. At small scale, a /catalog directory in the repo plus a build-time index is enough. Once the catalog grows past a few hundred entries, or once you need queries like "every endpoint touched by the dispute flow that returns a 4xx," it pays to load the same YAML into a graph database such as Neo4j or Dgraph and let the agent query it directly.
How the two layers work together
Neither layer is useful on its own. Per-endpoint metadata gives the agent a rich description of what an endpoint does but nothing about what it connects to. The catalog gives the agent a graph of relationships but nothing concrete to fill into a page. Documentation comes out of the place where the two meet.
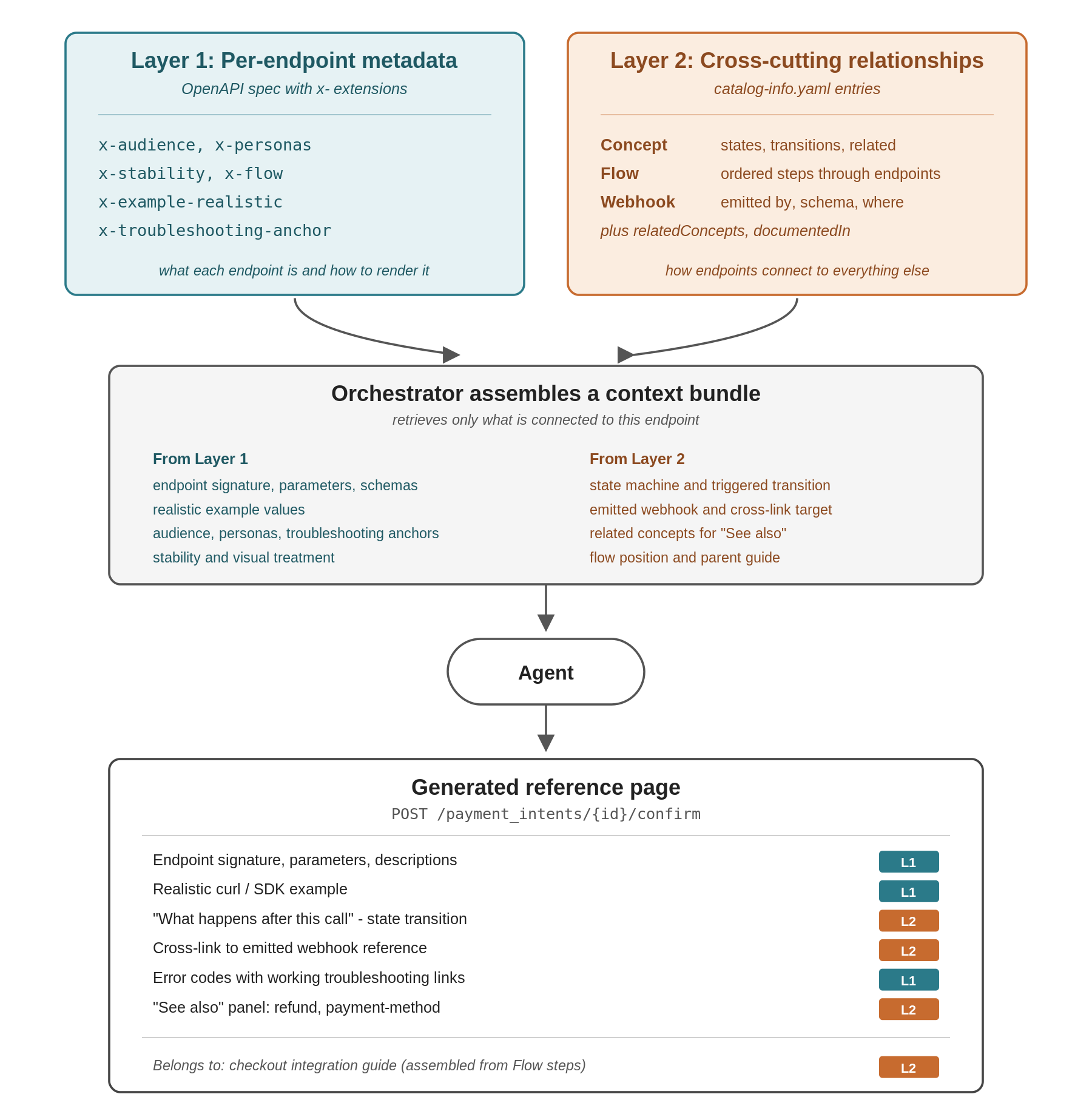
When the orchestrator decides to generate the reference page for POST /payment_intents/{id}/confirm., the first thing it does is build a context bundle for the agent:
- From the OpenAPI spec - it pulls the endpoint signature, the parameters, the request and response schemas, and the
x- extensionsat every level:x-audience:developer,x-personas: [merchant, marketplace],x-flow:checkout, the x-example-realistic values for every parameter, and thex-troubleshooting-anchoron each error response. - From the catalog - it pulls every entry that references this endpoint. The payment-intent Concept matches because one of its transitions has
triggeredBy: POST /payment_intents/{id}/confirm. That match brings along the surrounding state machine, the payment_intent.processing webhook the transition emits, therelatedConceptslist, and the integration guide the concept is documented in. The checkout Flow matches because the endpoint is one of its steps, and that match brings the position of the endpoint within the flow.
The agent now has everything it needs:
- It writes the reference page using the realistic values from Layer One.
- It adds a "What happens after this call" section describing the move from requires_action to processing, taken from Layer Two.
- It cross-links to the payment_intent.processing webhook reference, taken from the transition's emits field.
- It renders a small state diagram beside the page header, generated from the Concept's states and transitions.
- It populates the "See also" panel with refund and payment-method.
- It attaches a working troubleshooting link to each error code.
- It tags the page as part of the checkout flow so the integration guide picks it up in the right slot.
Automating the documentation maintenance
Now let’s see how the ontology works when changes are introduced:
- Renaming a parameter - when an engineer renames a parameter, only Layer One changes, and only that endpoint's reference page regenerates.
- New state transition - when an engineer adds a new state transition, only Layer Two changes, but every page connected to the payment-intent concept rebuilds along with the state diagram, and the checkout guide rebuilds if the transition lives on the flow.
- New webhook - when a new webhook is added to the catalog, the webhook's own reference page generates from scratch, and every endpoint that emits it picks up an automatic cross-link. The dependency map is implicit in the ontology. Nobody has to maintain it by hand.
Conclusion
As part of the new role of the technical writer, the writer's judgment does not live in the writing of any single page. It lives in the shape of the two layers, in the choice of which fields belong on the endpoints, which kinds of entries belong in the catalog, and which relationships are worth modelling. Once the upstream choices are made well, the agent can be trusted to apply them consistently across thousands of pages, and the writer is freed to spend their time on the work that scales: designing the system that produces the documentation, not writing the documentation itself.